An essential task for an autonomous robot deployed in the open world without prior knowledge about its environment is to perform Simultaneous Localization and Mapping (SLAM) to facilitate planning and navigation. Classical methods typically rely on handcrafted, low-level features, which tend to fail under challenging conditions, e.g., textureless regions. Deep learning-based approaches mitigate such problems due to their ability to learn high-level features. However, they lack the ability to generalize to out-of-distribution data, with respect to the training set. Such out-of-distribution data with regards to visual SLAM can, for instance, correspond to images sourced from cities in different countries or from substantially different environmental conditions, e.g., summer versus winter.
Continual SLAM
Beyond Lifelong Simultaneous Localization and Mapping through Continual Learning

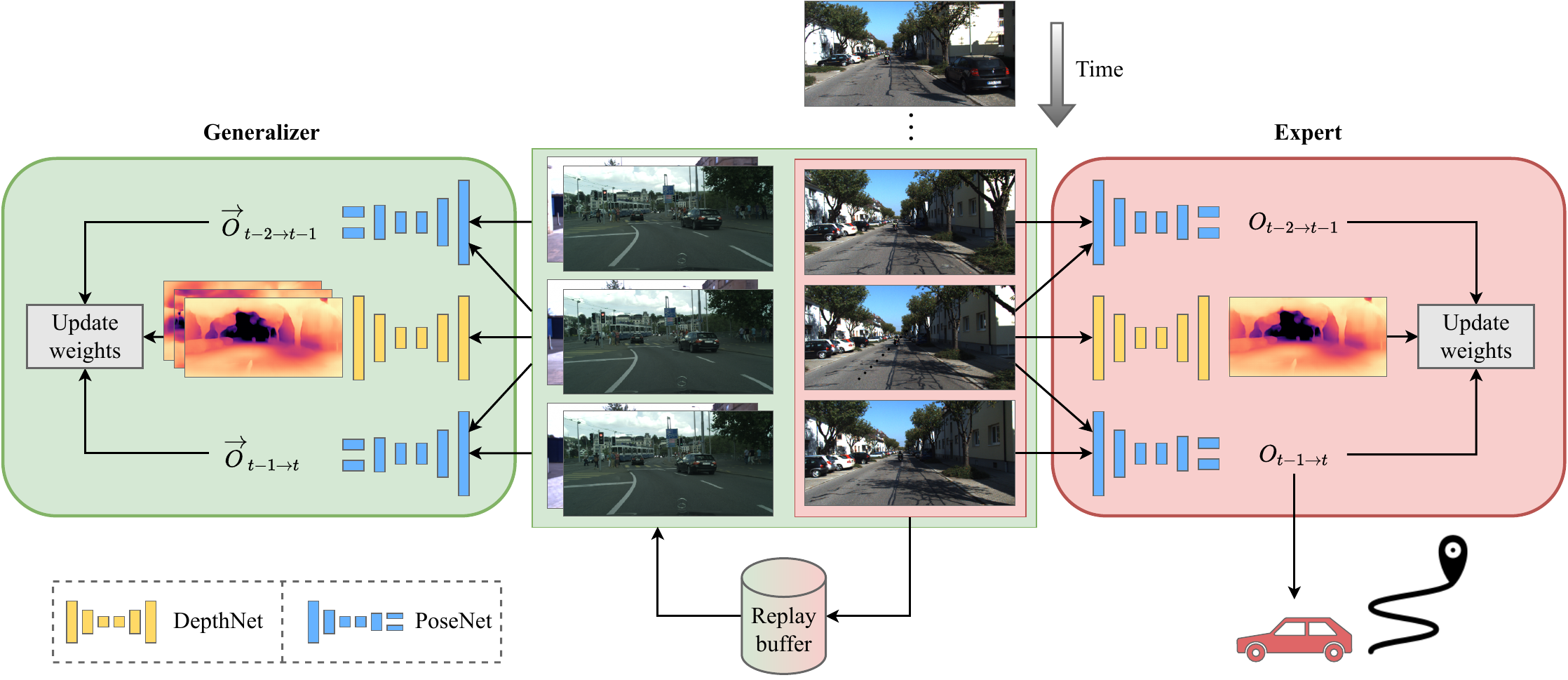
In the context of this work, lifelong SLAM considers the long-term operation of a robot in a dynamically changing environment. Although this environment can be altered over time, the robot is constrained to stay within a single bounded environment, e.g., to obtain continuous map updates within a city. Recent works attempt to relax this assumption by leveraging domain adaptation techniques for deep neural networks. While a naive solution for adapting to a new environment is to source additional data, this is not feasible when the goal is to ensure the uninterrupted operation of the robot. Moreover, changes in environments can be sudden, e.g., rapid weather changes, and data collection and annotation often come at a high cost. Therefore, adaption methods should be trainable in an unsupervised or self-supervised manner without the need for ground truth data. As illustrated in the figure above, the setting addressed in domain adaptation only considers unidirectional knowledge transfer from a single known to a single unknown environment and thus does not represent the open world, where the number of new environments that a robot can encounter is infinite and previously known environments can be revisited.
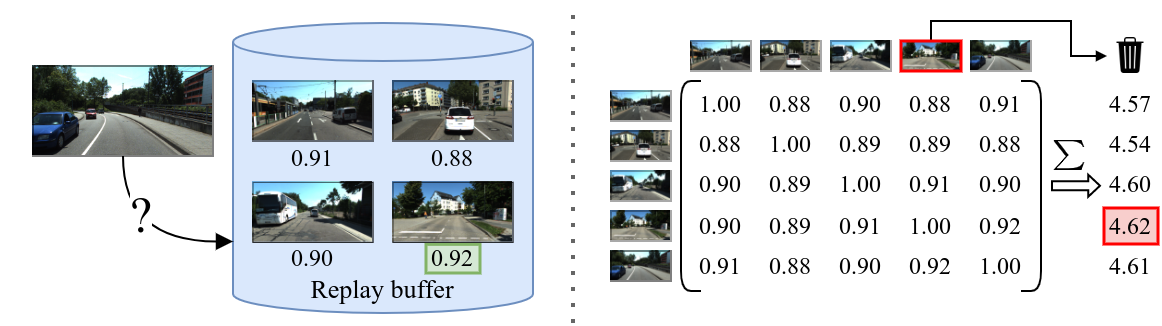
To overcome this gap, we propose a new task called continual SLAM, where the robot is deployed on a sequence of diverse scenes from different environments. Ideally, a method addressing the continual SLAM problem should be able to achieve the following goals: 1) quickly adapt to unseen environments while deployment, 2) leverage knowledge from previously seen environments to speed up the adaptation, and 3) effectively memorize knowledge from previously seen environments to minimize the required adaptation when revisiting them.